

Google’s Cloud Datastore is a database platform that applications access directly through API calls, most commonly via the Google App Engine. Google is in the process of replacing it with Google Cloud Firestore, which is the next-generation version.
When you choose the versions you want, it is important to consider the pros and cons of each service:
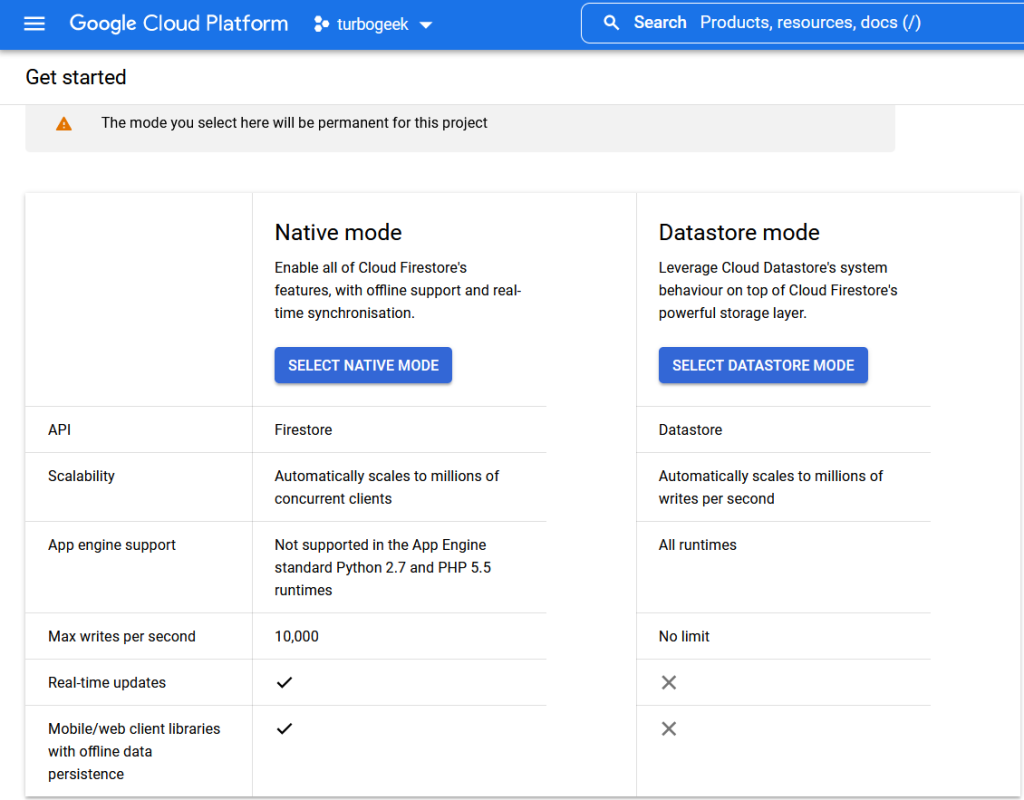
Background Information on Datastore
Multiple data centers actively replicate data, ensuring that query performance scales proportionally to the size of the result set. This architecture prevents slowdowns, even when managing extremely large volumes of data in the database.
Cloud Datastore has evolved into a product offering strong consistency. Users can configure it for regional or multi-regional replication to enhance reliability and performance.
When would you use Cloud Datastore?
- The scheme can be changed.
- Database is adaptable
- Can scale down to zero
- Fairly cheap – first 1 GB is free
- Fully transactional DB
| Concept | Cloud Datastore | Cloud Firestore | Relational database |
|---|---|---|---|
| Category of object | Kind | Collection group | Table |
| One object | Entity | Document | Row |
| Individual data for an object | Property | Field | Column |
| Unique ID for an object | Key | Document ID | Primary key |
- Cloud Datastore automatically scales to accommodate large data sets, enabling applications to sustain high-performance levels as traffic increases.
- Cloud Datastore writes scale by automatically distributing data as necessary.
- Cloud Datastore reads scale because the only queries supported are those whose performance scales with the size of the result set (as opposed to the data set). This means that a query whose result set contains 100 entities performs the same whether it searches over a hundred entities or a million. This property is the key reason some types of queries are not supported.
- Pre-built indexes handle all queries, making the query types more restrictive than those in a relational database that uses SQL. In particular, Cloud Datastore does not include support for join operations, inequality filtering on multiple properties, or filtering on data based on results of a subquery.
- Unlike traditional relational databases which enforce a schema, Cloud Datastore is schemaless. It doesn’t require entities of the same kind to have a consistent set of properties (although you can choose to enforce such a requirement in your own application code).
Leave a Reply