

TL;DR
- What eBPF is — A kernel technology that lets you run sandboxed programs inside the Linux kernel without modifying source code or loading kernel modules.
- Why it matters for security — Deploy and update kernel-level security policies dynamically, with zero downtime and no recompilation.
- Key tools — Cilium (networking), Tetragon (runtime enforcement), Falco (threat detection), seccomp-bpf (syscall filtering).
- Getting started — Check kernel support with
bpftool, install Cilium or Tetragon, and write your first eBPF security policy.
New to Linux kernel security? Start with the What Is eBPF? section below, then jump to Getting Started for hands-on steps.
| Topic | When to Use | Key Tool / Command |
|---|---|---|
| Network policy enforcement | Kubernetes pod-to-pod traffic control | Cilium |
| Runtime threat detection | Detecting anomalous process behaviour | Tetragon / Falco |
| Syscall filtering | Restricting container attack surface | seccomp-bpf |
| File integrity monitoring | Watching critical files for tampering | Tetragon / custom eBPF |
| Process auditing | Full process tree visibility | bpftrace / Hubble |
| Check kernel eBPF support | Before deploying any eBPF tool | bpftool feature probe |
What Is eBPF?
Extended Berkeley Packet Filter (eBPF) is a technology built into the Linux kernel that lets you run sandboxed programs at kernel level without modifying kernel source code, loading kernel modules, or rebooting the system. Originally designed for packet filtering, eBPF has evolved into a general-purpose in-kernel virtual machine capable of handling networking, observability, and — crucially — security.
Think of eBPF as a programmable layer sitting between your applications and the kernel. When a system call fires, a network packet arrives, or a file is opened, eBPF programs can inspect, filter, and act on those events in real time. The kernel’s built-in verifier guarantees that every eBPF program is safe before it runs: no infinite loops, no invalid memory access, no kernel crashes.
This combination — kernel-level access with safety guarantees — is what makes eBPF transformative for security. You get the performance of kernel-native enforcement with the flexibility of user-space tooling.
How eBPF Works: The Architecture
Understanding eBPF’s architecture is essential before deploying it for security. The flow from user space to kernel execution involves four key stages.
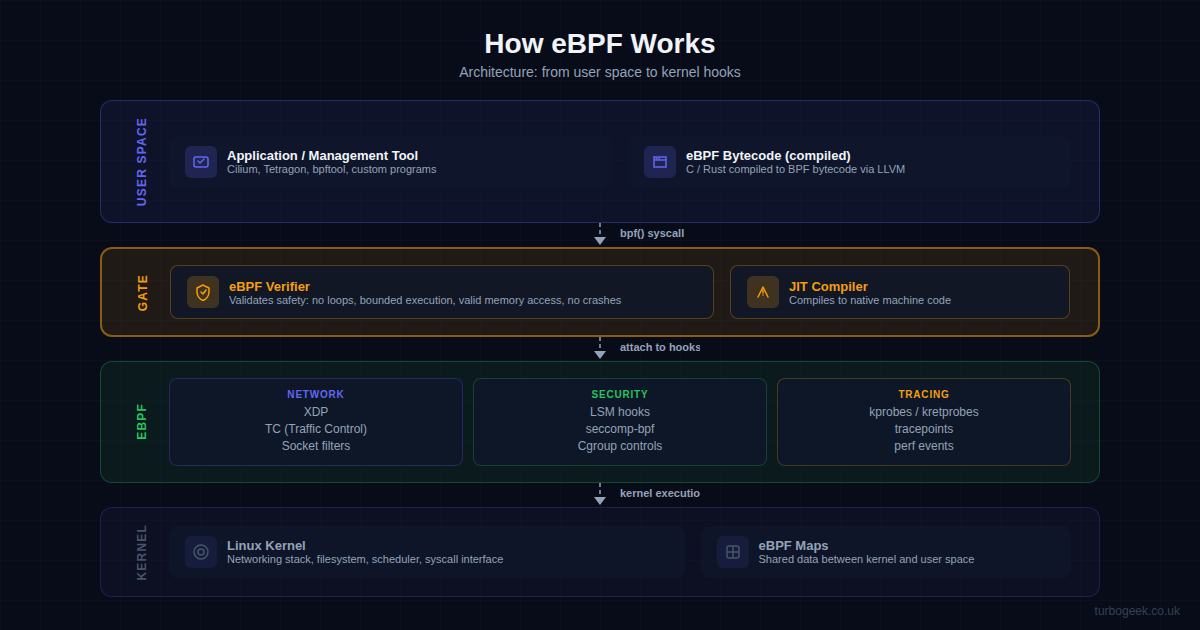
1. Compilation. You write eBPF programs in C or Rust, which LLVM compiles into eBPF bytecode. Tools like Cilium and Tetragon ship pre-compiled programs, so you rarely need to write raw eBPF code yourself.
2. Loading and verification. The bytecode is loaded into the kernel via the bpf() system call. Before it can run, the kernel’s eBPF verifier performs static analysis: it checks for bounded loops, validates all memory accesses, ensures the program terminates, and confirms it cannot crash the kernel. If verification fails, the program is rejected — no exceptions.
3. JIT compilation. Once verified, the bytecode is just-in-time compiled to native machine code for near-zero overhead execution.
4. Attachment to hooks. The compiled program attaches to one or more kernel hook points. For security, the most relevant hooks are:
- LSM hooks — Linux Security Module attachment points for access control decisions.
- XDP (eXpress Data Path) — Processes packets at the network driver level before the kernel networking stack.
- TC (Traffic Control) — Filters and shapes traffic within the kernel networking stack.
- kprobes / tracepoints — Dynamic and static instrumentation points for tracing kernel function calls.
- seccomp-bpf — Filters system calls per process, restricting which syscalls a container or application can invoke.
The Verifier: Why eBPF Is Safe
The most common objection to running custom code inside the kernel is safety. Kernel modules can crash your entire system. eBPF solves this with a mandatory verification step that no program can bypass.
The verifier performs several checks before allowing a program to run:
- Termination guarantee — All loops must be bounded. The verifier proves that the program will finish executing within a predictable number of instructions.
- Memory safety — Every pointer dereference is validated. Out-of-bounds access is rejected at load time, not at runtime.
- No kernel state corruption — eBPF programs can only access kernel data through well-defined helper functions. Direct kernel memory manipulation is impossible.
- Privilege requirements — Loading eBPF programs requires
CAP_BPF(orCAP_SYS_ADMINon older kernels), preventing unprivileged users from attaching code to the kernel.
This safety model means you can deploy, update, and remove security policies at runtime without any risk of destabilising the kernel. Compare that with traditional kernel modules, where a single bug can bring down the entire system.
eBPF Security Use Cases
eBPF’s flexibility means it powers a wide range of security tools. Here are the six most impactful use cases for Linux sysadmins today.

1. Network Policy Enforcement with Cilium
Cilium replaces traditional iptables-based networking in Kubernetes with eBPF programs that run directly in the kernel datapath. It enforces identity-aware network policies at L3, L4, and L7 — meaning you can write policies based on service identity rather than IP addresses. Performance is dramatically better than iptables at scale because eBPF avoids the linear rule-matching overhead.
2. Runtime Threat Detection with Tetragon and Falco
Tetragon (from Isovalent/Cisco) and Falco (from Sysdig/CNCF) use eBPF to monitor kernel events in real time. They can detect privilege escalation attempts, unexpected process executions, sensitive file access, and network connections to known-bad destinations — all without any kernel module or agent running in the container itself.
Tetragon goes further by offering enforcement in addition to detection: it can kill a process or deny a system call at the kernel level the moment a policy violation is detected, before the malicious action completes.
3. Syscall Filtering with seccomp-bpf
Every container runtime (Docker, containerd, CRI-O) uses seccomp-bpf profiles to restrict which system calls a container can make. The default Docker seccomp profile blocks around 44 of the 300+ Linux syscalls, preventing containers from calling dangerous functions like reboot(), mount(), or kexec_load(). You can write custom profiles to further tighten the attack surface for specific workloads.
4. File Integrity Monitoring
Traditional file integrity monitoring tools (AIDE, OSSEC) work by periodically scanning file checksums. eBPF-based monitoring hooks directly into the kernel’s VFS layer, catching file opens, writes, and permission changes the instant they happen. There is no polling interval to miss, and the overhead is negligible compared to scan-based approaches.
5. Process Visibility and Auditing
Tools like Hubble and bpftrace provide full process tree tracing with parent-child relationships, command-line arguments, and environment variable capture. This gives security teams complete visibility into what runs on a system without relying on user-space logging that an attacker could tamper with.
6. Container Security Boundaries
eBPF enables per-pod and per-namespace security policies that are enforced at the kernel level. Tools like Cilium and KubeArmor can prevent container escapes, block access to the host filesystem, restrict network egress, and enforce least-privilege at a granularity that traditional Linux capabilities and seccomp profiles cannot match alone.
Getting Started with eBPF Security
You do not need to write eBPF programs from scratch. The ecosystem has matured to the point where established tools handle the complexity. Here is how to get started.
Check Your Kernel
eBPF requires Linux kernel 4.x or later, but for security features (particularly LSM hooks), you want kernel 5.7 or newer. Check your support level:
Install Cilium (Kubernetes Networking + Security)
If you are running Kubernetes, Cilium is the single most impactful eBPF tool you can deploy. It replaces kube-proxy and your CNI plugin while adding network policy enforcement:
Install Tetragon (Runtime Security)
Tetragon provides kernel-level runtime enforcement. You can run it standalone on any Linux host or deploy it as a DaemonSet in Kubernetes:
Write a Basic Tetragon Policy
Here is a Tetragon TracingPolicy that detects and logs any process that reads /etc/shadow — a common indicator of credential harvesting:
With this policy active, any attempt to read /etc/shadow generates a kernel-level event that Tetragon forwards to your logging pipeline. You can extend this to block the action entirely by adding an matchActions block with action: Sigkill.
eBPF vs Traditional Kernel Security
To understand why eBPF is gaining adoption so quickly, compare it with the traditional approaches it replaces:
| Aspect | Traditional (Modules / iptables) | eBPF |
|---|---|---|
| Deployment | Kernel recompile or module load | Dynamic load via bpf() syscall |
| Safety | Can crash the kernel | Verifier guarantees safety |
| Updates | Reboot often required | Hot-swap at runtime |
| Performance | iptables degrades at scale | JIT-compiled, near-native speed |
| Granularity | IP/port-level policies | Identity-aware, L7-capable |
| Observability | Separate tooling required | Built into the same framework |
What to Watch in 2026
The eBPF ecosystem is moving fast. Key developments to track this year:
- eBPF on Windows — Microsoft’s eBPF for Windows project continues to mature, bringing cross-platform eBPF tooling closer to reality.
- Kernel 6.x improvements — Recent kernels have expanded BPF LSM support, added signed eBPF programs, and improved the verifier’s ability to handle complex policies.
- CNCF graduation — Cilium is now a CNCF graduated project, and Falco and Tetragon continue to gain enterprise adoption.
- Supply chain security — Expect to see eBPF used for runtime software supply chain verification, detecting tampered binaries at execution time.
Summary
eBPF fundamentally changes how Linux security works. Instead of static firewall rules, kernel module risks, and reboot-heavy deployments, you get dynamic, verifier-guaranteed, runtime-swappable security policies that operate at kernel speed. The tooling — Cilium for networking, Tetragon for runtime enforcement, Falco for detection, seccomp-bpf for syscall filtering — is production-ready and backed by major organisations.
If you are managing Linux servers or Kubernetes clusters, eBPF-based security is no longer experimental. It is the direction the industry is moving, and the tools are ready for production today.
Leave a Reply