

TL;DR — Is Claude Code Safe?
- Privacy — only what is in your active session is sent; API data is not used for model training by default
- Code quality — it can write insecure code; treat the output like a PR that needs review
- Practical hygiene — use
.claudeignore, keep secrets out of context, review before merging - The verdict — manageable risks with basic practices; most developers can adopt it safely
IN THIS SERIES
Every time I recommend Claude Code to another developer, two questions come up before anything else — not “how does it work” or “what does it cost,” but two questions about trust. Does Anthropic see my code? And can I actually trust what it writes? Both concerns are legitimate. Here are honest answers to both.
New to Claude Code? Start with What is Claude Code? — this post assumes you know the basics.
Concern 1: Data Privacy
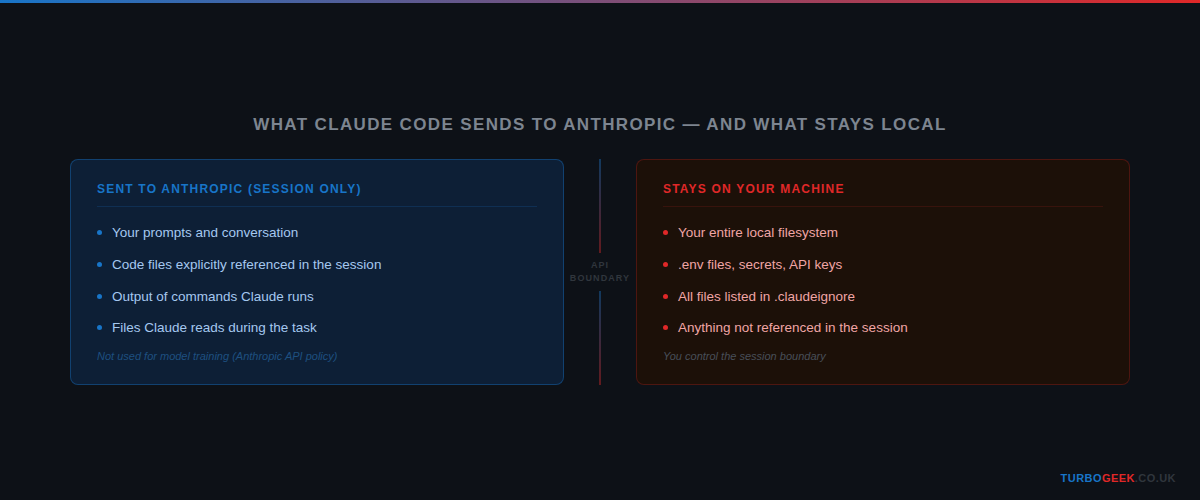
When you use Claude Code, what gets sent to Anthropic is what is in your active session — the prompts you type, the code you have referenced, the output of commands you have run. What does not get sent is your entire filesystem. Claude Code does not silently scan and upload your codebase in the background.
On training data: per Anthropic’s usage policies, data submitted via the API is not used to train models by default. Claude Code works via the API. Your code does not become training data.
That said, the session boundary is the thing to be deliberate about. If you paste a database connection string into the chat, or ask Claude Code to read a file containing API keys, that content is in the session and is transmitted. The same discipline you apply to committing secrets to git applies here: keep them out of context entirely.
For sensitive projects, the practical hygiene is straightforward. Create a .claudeignore file at your project root with any paths you want excluded from context:
The .claudeignore format mirrors .gitignore — if you already know one, you know the other. Set it up once and you will not think about it again. Do not paste your .env. Do not reference credential files. Keep sensitive configuration out of the conversation.
If you work in a regulated industry — financial services, healthcare, anything with strict data residency requirements — apply the same scrutiny you would apply to any third-party cloud tooling. Read the Anthropic privacy policy. Understand what a session includes. Make an informed decision, not an anxious one.
One practical note for teams: add .claudeignore to your project template or repository scaffolding so it is present by default on every new project. It takes sixty seconds to set up and means you never have to remember to add it later, when the pressure to ship is higher and the tendency to skip hygiene steps is greater.

Concern 2: Code Quality and Security
Claude Code can write insecure code. I want to be direct about this: it is not a security scanner, it does not know your specific threat model, and it does not replace code review. If you treat its output as production-ready without checking it, you will eventually merge something you should not have.
The mental model that works for me: treat Claude Code like a capable junior developer. The code is usually good. Sometimes it is very good. Occasionally there is something you would catch in review — a missing input validation, an overly permissive database query, an unhandled error case. The review catches those. You would not merge a junior developer’s PR without reading it. Same principle here.
The specific failure modes to watch for are the usual suspects: SQL injection in dynamically-constructed queries, missing authentication checks on new API endpoints, secrets hardcoded into test fixtures, overly broad CORS configuration. These are not unique to AI-generated code — they are the same mistakes developers make under time pressure. The difference is that Claude Code works fast, so if you skip review entirely you will accumulate them fast too.
Two skills from the Claude Code skills system help significantly with this:
- The requesting-code-review skill has Claude check its own work against the original plan and coding standards before you see it — it catches drift and quality issues before they reach you
- The verification-before-completion skill prevents Claude from claiming something is working until it has actually run the code and confirmed the output — no more “it should work” without evidence
Both of these are covered in detail in the 7 Claude Code Skills post.
Related: Secure AI Coding in Practice: A DevSecOps Checklist for 2026 — a practical checklist for teams integrating AI coding tools into security-conscious workflows.
The Honest Verdict
I run production code through Claude Code every day. My approach is not paranoid and it is not reckless: I am careful about what I put in context, I review what it produces, and I use the built-in review skills for anything that matters. That is not much overhead compared to what I get in return.
The framing I keep coming back to: the risks here are not fundamentally different from risks you already accept. You push code to GitHub — a third party holds your source. You run npm install — you trust packages written by strangers. You use a cloud CI system — your test environment runs on someone else’s infrastructure. Claude Code adds one more boundary to think about. You manage it the same way you manage the others: with deliberate hygiene, not anxiety.
For most developers working on most projects, the concerns are manageable with basic hygiene. A .claudeignore file, a code review habit, and an understanding of what the session boundary means. That is genuinely not much to ask for the productivity gain on the other side.
The risks are real. They are also the same category of risk you accepted when you started pushing code to GitHub, using a cloud CI system, or running npm install. Manageable with care, not a reason to opt out.
Once you have worked through those concerns and landed somewhere you are comfortable with, something shifts in how you work. That shift is what the next post is about.
Leave a Reply